










1. はじめに
先日AWSとVue.jsでアプリケーションを開発する機会がありましたので個人的に重要だと感じた点や躓いた点をまとめました。参考になれば幸いです。
2. 目次
- 1. はじめに
- 2. 目次
- 3. 概要
- 4. 各種AWSリソースのセットアップ
- 5. フロントエンド側のセットアップ
- 6. 検証
- 7. おわりに
3. 概要
3.1. アーキテクチャ図
以下が本アプリケーションのアーキテクチャ図となります。

3.2. ダイアグラム図
以下が本アプリケーションの処理フローを示すダイアグラム図となります。

①Vue.jsで画像ファイルを選択することでAPI Gatewayを経由してLambdaに署名付きURLをリクエストしてLambdaが署名付きURLを発行
➁API Gatewayを経由してVue.jsでLambdaから署名付きURLを受け取り
③Vue.jsで署名付きURLを使用して画像をS3にアップロード
④Vue.jsでAPI Gatewayを経由してLambdaにRekognitionで検出されたラベルと各ラベルに対する信頼度とバウンディングボックスの情報を取得してRDSに書き込むことをリクエスト
⑤LambdaがRekognitionを使用して画像から検出されたラベルと各ラベルに対する信頼度とバウンディングボックスの情報を取得
⑥Lambdaがpsycopg2を使用してAmazon RDSに接続して画像から検出されたラベルと各ラベルに対する信頼度とバウンディングボックスの情報を書き込んだ後Amazon RDSとの接続を解除
⑦API Gatewayを経由してVue.jsでLambdaからRekognitionとAmazon RDSでの作業が終了した報告を受け取り
⑧Vue.jsでAPI Gatewayを経由してLambdaにAmazon RDSに存在するデータベースのテーブルの情報を取得することリクエスト
⑨Lambdaがpsycopg2を使用してAmazon RDSに接続してデータベースに存在するテーブルの情報を取得
⑩API Gatewayを経由してVue.jsでLambdaからデータベースのテーブルの情報を受け取り
3.3. ランタイム設定
本アプリケーションは以下のランタイム設定で動作を検証済です。
- AWS全般
- リージョン:ap-northeast-1(東京)
- Amazon RDS
- データベースエンジン:PostgreSQL
- バージョン:14.4
- データベースエンジン:PostgreSQL
- AWS Lambda
- 関数言語:Python
- バージョン:3.8
- Lambdaレイヤーのパッケージ:psycopg2
- バージョン:2.9.6
- 関数言語:Python
4. 各種AWSリソースのセットアップ
4.1. Amazon S3
4.1.1. Amazon S3とは
まずAmazon S3に関して簡単に解説します。
Amazon S3はAWSが提供するクラウドストレージサービスです。
S3には以下のような特徴や利点があります。
■スケーラビリティ(拡張性):
必要に応じてストレージを増やしたり減らすことができます。
■ 信頼性と耐久性:
データが複数の物理的な場所に冗長に保存されるため一部のハードウェアや場所が障害を起こした場合でも、データは安全に保護されます。
■セキュリティ:
アクセス権限の制御やデータの暗号化など、ユーザーが自分のデータを安全に保つための多くのツールを提供します。
■ 使いやすさ:
ウェブブラウザから直接アクセスしたり、プログラムを使って自動化したりすることができます。
■コスト効率:
未使用のリソースに対して費用を払うことはありません。
詳細は以下のAWSの公式ドキュメントをご覧下さい。
4.1.2. Amazon S3の設定
次に本アプリケーションに必要なS3の設定を具体的に解説します。 WebアプリケーションをS3上に公開する手順は本ブログの過去の記事に存在しますので以下をご覧ください。
ただし、1点追加事項があります。
それはCORS設定です。本アプリケーションはVue.jsからS3に画像ファイルをアップロードするので異なるオリジンからのアクセスとなるためにCORS設定が必要となります。以下に本アプリケーションで使用したCORS設定を示します。
[ { "AllowedHeaders": [ "Content-Type", "Authorization", "X-Amz-Date", "X-Amz-Security-Token", "X-Api-Key" ], "AllowedMethods": [ "GET", "POST", "PUT", ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [], "MaxAgeSeconds": 3000 } ]
上記のCORS設定に関して解説します。
■AllowedHeaders:
必要なヘッダーだけを許可するようにして下さい。ワイルドカードを使用すれば全てのヘッダーが許可されますが、セキュリティ上のリスクが増大します。
■AllowedMethods:
必要なHTTPメソッドだけを許可して下さい。本アプリケーションではGETメソッドとPOSTメソッドとPUTメソッドを使用するので、この3つのメソッドを許可しています。
■AllowedOrigins:
本アプリケーションが全世界からのアクセスを許可していると仮定してワイルドカードを使用しています。しかし、特定のドメインやサブドメインからのアクセスだけを許可する方がセキュリティ上当然好ましいです。
4.2. Amazon VPC
4.2.1. Amazon VPCとは
まず Amazon VPCに関して簡単に解説します。
Amazon VPCはAWSが提供するクラウドネットワーキングサービスの一つです。VPCを使用するとAWS上にプライベートな仮想ネットワーク環境を作成できます。AWSのリソース(サーバー、データベースなど)をこのネットワーク内でセキュアに運用することが可能となります。
Amazon VPCには以下のような特徴や利点があります。
■セキュリティ:
自分だけの仮想ネットワーク環境を作成でき、その中でAWSのリソースを運用できます。これにより、外部からのアクセスを制限し、自分のリソースにアクセスできる人やサービスを厳密に制御できます。
■カスタマイズ可能:
IPアドレス範囲の選択、サブネットの作成、ルーティングテーブルの設定、ネットワークゲートウェイの設置など、 自分のネットワークを自由に設定できます。
■接続性:
オンプレミス(自社内)のネットワークと安全に接続することも可能です。これにより、クラウド上と自社内のネットワークをシームレスにつなげ、一つの大きなネットワークとして扱うことができます。
■スケーラビリティ:
ビジネスが成長するにつれて簡単に拡大することができます。新たなサブネットを追加したり、より大きなIPアドレス範囲を設定したりすることが可能です。
詳細は以下のAWSの公式ドキュメントをご覧下さい。
4.2.2. Amazon VPCの設定
次に本アプリケーションに必要なVPCの設定を具体的に解説します。
VPCやサブネットやセキュリティグループを作成する手順は本ブログの過去の記事に存在しますので以下をご覧ください。
ただし、追加事項が3点存在します。
1点目はAmazon RDS用のセキュリティグループです。PostgreSQLのポート範囲は5432なので、インバウンドルールにおいて、これ以外のポート範囲を許可するのはセキュリティ上のリスクが上昇します。またアウトバウンドルールはデフォルトでは全ての通信を許可する設定になっていますが、特定のIPアドレスやIPアドレス範囲へのアウトバウンドトラフィックのみを許可するように変更することも検討して下さい。
2点目はLambdaからS3にアクセスするためのVPCエンドポイントです。本アプリケーションではLambdaがVPC内に存在するため、VPCエンドポイントを介さなければS3にアクセスすることができません。以下にVPC内のLambdaからS3へのアクセスに必要なVPCエンドポイントの作成方法を示します。まずAWSマネジメントコンソールのホームからVPCを選択します。次に画面左側のメニューから「エンドポイント」を選択して画面右上の「エンドポイントを作成」を選択して下さい。
 次にそれぞれの項目は以下のように設定して下さい。
次にそれぞれの項目は以下のように設定して下さい。
●サービスカテゴリ:AWSのサービス
●サービス:「com.amazonaws.[リージョン名].s3」でタイプ「Gateway」
●VPC:Lambdaを配置予定のVPCを選択
●ルートテーブル:エンドポイントを関連付けたいルートテーブルのIDを指定
●ポリシー:フルアクセス

3点目はLambdaからRekognitionにアクセスするためのVPCエンドポイントです。本アプリケーションではLambdaがVPC内に存在するため、VPCエンドポイントを介さなければRekognitionにアクセスすることができません。以下にVPC内のLambdaからRekognitionへのアクセスに必要なVPCエンドポイントの作成方法を示します。まずAWSマネジメントコンソールのホームからVPCを選択します。次に画面左側のメニューから「エンドポイント」を選択して画面右上の「エンドポイントを作成」を選択して下さい。
次にそれぞれの項目は以下のように設定して下さい。
●サービスカテゴリ:AWSのサービス
●サービス:「com.amazonaws.[リージョン名].rekognition」でタイプ「Interface」
●VPC:Lambdaを配置予定のVPCを選択
●アベイラビリティゾーン: 自分のリージョンを選択
●サブネットID:エンドポイントに関連付けるVPCのサブネットを選択します。Lambdaを配置予定サブネットを選択
●IPアドレスタイプ:IPv4
●セキュリティグループ:Lambdaからのアクセスを許可するように設定されたセキュリティグループを選択
●ポリシー:フルアクセス
 ちなみにアーキテクチャ図ではLambdaからRekognitionにアクセスするためのVPCエンドポイントをPrivateLinkと表示していますが、これはInterface型のVPCエンドポイントにはPrivateLink技術を使用しているためです。
ちなみにアーキテクチャ図ではLambdaからRekognitionにアクセスするためのVPCエンドポイントをPrivateLinkと表示していますが、これはInterface型のVPCエンドポイントにはPrivateLink技術を使用しているためです。
4.3. Amazon RDS
4.3.1. Amazon RDSとは
まず Amazon RDSに関して簡単に解説します。
Amazon RDSはAWSが提供するリレーショナルデータベースの管理サービスです。
Amazon RDSには以下のような特徴や利点があります。
■マネージドサービス:
データベースをセットアップ、運用、スケールする作業をAWSが行います。
■スケーラビリティ:
データベースが大きくなった場合やトラフィックが増えた場合でも、簡単にリソースを追加したり、データベースの性能を向上させることができます。
■高い可用性と耐久性:
データベースを複数の物理的な場所に分散させることで、一部のインフラがダウンした場合でもデータベースが稼働し続けるという仕組みです。また、自動バックアップとポイントインタイムリストアの機能により、データの耐久性も確保されます。
■セキュリティ:
データの暗号化、ネットワーク隔離、アクセス管理など、多数のセキュリティ機能を提供しています。
■互換性:
多くの主要なデータベースエンジン(MySQL、PostgreSQL、MariaDB、Oracle、SQL Serverなど)をサポートしています。
詳細は以下のAWSの公式ドキュメントをご覧下さい。
4.3.2. Amazon RDSの設定
次に本アプリケーションに必要なRDSの設定を具体的に解説します。
まずAWSマネジメントコンソールのホームからRDSを選択します。
次に画面上部の「データベースの作成」を選択して下さい。
 次に、それぞれの項目は以下のように設定して下さい。
次に、それぞれの項目は以下のように設定して下さい。
●エンジンのオプション:PostgreSQL
●パブリックアクセス:なし
●VPC:Lambdaを配置予定のVPC
●サブネット:Lambdaを配置予定サブネットを選択
●セキュリティグループ:Lambdaからのアクセスを許可するように設定されたセキュリティグループを選択
●最後に「データベースの作成」を選択して下さい。

4.4. Amazon Rekognition
4.4.1. Amazon Rekognitionとは
まず Amazon Rekognitionに関して簡単に解説します。
Amazon RekognitionはAWSが提供するディープラーニングに基づく画像およびビデオ分析サービスです。画像や動画から情報を認識・分析するためのAI(人工知能)技術を利用しています。
Amazon Rekognitionには以下のような特徴や利点があります。
■画像とビデオの認識:
画像やビデオから物体、人、テキスト、シーン、活動などを認識することができます。
■顔認識と分析:
画像内の顔を検出し、その特性や感情を分析することができます。さらに、異なる画像や動画の中で同一の顔を認識(顔マッチング)する機能もあります。
■フルマネージドサービス:
ユーザーは深層学習や画像分析の専門知識がなくてもこれらの高度な機能を利用することが可能です。
■スケーラビリティ:
数枚の画像から何百万もの画像まで、あらゆるスケールのデータに対応できます。
■ インテグレーション:
他のAWSサービスとシームレスに統合できます。たとえば、分析結果をAmazon S3に保存したりAWS Lambdaを使って結果に基づくアクションを自動化したりすることが可能です。本アプリケーションもこの機能を利用しています。
詳細は以下のAWSの公式ドキュメントをご覧下さい。
4.4.2. Amazon Rekognitionの設定
次に本アプリケーションに必要なRekognitionの設定を具体的に解説します。
深層学習を利用するサービスなので非常に難しい設定が必要かと思いきや実は、本アプリケーションではRekognition APIを使用しているため、AWSマネジメントコンソール上の「Amazon Rekognition」のページで全く何の設定もしなくても使用できます。もちろんフロントエンド側(本アプリケーションではVue.js)でAPIを叩くコードは必要です。
4.5. AWS Lambda
4.5.1. AWS Lambdaとは
まず AWS Lambdaに関して簡単に解説します。
AWS LambdaはAWSが提供する「サーバーレス」コンピューティングサービスです。サーバーレスとは、ユーザーがサーバーの管理やスケーリング(拡張)などに関して気にすることなく、コードの実行に集中できるようなコンピューティングモデルを指します。※サーバーが存在しないという意味ではありません。
AWS Lambdaには以下のような特徴や利点があります。:
■ サーバーレス:
サーバーレスコンピューティングサービスなので、ユーザーはサーバーのプロビジョニングや管理をする必要がありません。
■イベントドリブン:
特定のイベント(例えば、ユーザーからのリクエストやデータベースの更新など)に反応してコードを自動的に実行します。
■自動スケーリング:
トラフィックの量に応じて自動的にスケーリングします。
■従量課金制:
料金は、実際にコードが実行された時間だけで計算されます。つまり、コードが実行されていない時は料金が発生しません。
■多言語対応:
Java, Go, PowerShell, Node.js, C#, Python, Rubyなど、複数のプログラミング言語に対応しています。
詳細は以下のAWSの公式ドキュメントをご覧下さい。
4.5.2. AWS Lambdaの設定
次に本アプリケーションに必要なAWS Lambdaの設定を具体的に解説します。
まずAWSマネジメントコンソールのホームからLambdaを選択します。Lambda関数とLambdaに必要なIAMポリシーを作成する手順は本ブログの過去の記事に存在しますので以下をご覧ください。
追加事項としては、本アプリケーションではLambdaがVPC内に存在するので、RDSが存在するVPCと同じVPCを選択してLambda関数を作成して下さい。また、当然IAMポリシーの内容は異なるので、以下に本アプリケーションのLambdaに必要なIAMポリシーを示します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket" ], "Resource": [ "「S3 ARN」", "「S3 ARN」/*" ] }, { "Effect": "Allow", "Action": [ "rekognition:DetectLabels" ], "Resource": "*" }, { "Effect": "Allow", "Action": "lambda:InvokeFunction", "Resource": "「Lambda ARN」" }, { "Effect": "Allow", "Action": [ "ec2:CreateNetworkInterface", "ec2:DescribeNetworkInterfaces", "ec2:DeleteNetworkInterface", "ec2:AssignPrivateIpAddresses", "ec2:UnassignPrivateIpAddresses" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "rds:DescribeDBInstances", "rds-data:ExecuteSql" ], "Resource": "「RDS ARN」" } ] }
「S3 ARN」と「Lambda ARN」と「RDS ARN」はそれぞれ自分が作成したAWSリソースのARNに置き換えて下さい。
次に本アプリケーションに必要なLambda関数を示します。
# 必要なライブラリをインポート import boto3 import json import psycopg2 import os # 環境変数からデータベース設定を取得 DATABASE_CONFIG = { 'database': os.environ['DB_NAME'], 'user': os.environ['DB_USER'], 'password': os.environ['DB_PASSWORD'], 'host': os.environ['DB_HOST'], 'port': os.environ['DB_PORT'], } # 環境変数からS3バケット名とRekognitionの設定を取得 S3_BUCKET = os.environ['S3_BUCKET'] REKOGNITION_MAX_LABELS = int(os.environ['REKOGNITION_MAX_LABELS']) REKOGNITION_MIN_CONFIDENCE = float(os.environ['REKOGNITION_MIN_CONFIDENCE']) # CORS設定 headers = { 'ContentType': 'application/json', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Headers': 'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token', 'Access-Control-Allow-Methods': 'GET,PUT,POST,OPTIONS', 'Access-Control-Allow-Credentials': 'true', } # Amazon RDSへの接続を作成する関数 def get_db_connection(): return psycopg2.connect(**DATABASE_CONFIG) # Amazon RDSのカーソルを作成する関数 def get_db_cursor(conn): return conn.cursor() # ラベル情報を保存するテーブルを作成する関数(テーブルが存在しない場合) def create_labels_table_if_not_exists(cur): cur.execute(""" CREATE TABLE IF NOT EXISTS labels ( id SERIAL PRIMARY KEY, file_name TEXT NOT NULL, label TEXT NOT NULL, confidence FLOAT NOT NULL, bounding_box_width FLOAT NOT NULL, bounding_box_height FLOAT NOT NULL, bounding_box_left FLOAT NOT NULL, bounding_box_top FLOAT NOT NULL ) """) # ラベル情報をテーブルに挿入する関数 def insert_label(cur, values): cur.execute(""" INSERT INTO labels (file_name, label, confidence, bounding_box_width, bounding_box_height, bounding_box_left, bounding_box_top) VALUES (%s, %s, %s, %s, %s, %s, %s) """, values) # S3から画像を取得し、Rekognitionでラベルを検出する関数 def detect_labels(s3_client, s3_resource, s3_bucket, s3_key): obj = s3_resource.Object(s3_bucket, s3_key) image_data = obj.get()["Body"].read() rekognition = s3_client.client('rekognition') return rekognition.detect_labels( Image={'Bytes': image_data}, MaxLabels=REKOGNITION_MAX_LABELS, MinConfidence=REKOGNITION_MIN_CONFIDENCE ) # Rekognitionの結果をRDSに書き込む関数 def write_labels_to_rds(response, s3_key): conn = get_db_connection() cur = get_db_cursor(conn) create_labels_table_if_not_exists(cur) try: for label in response['Labels']: for instance in label['Instances']: boundingBox = instance['BoundingBox'] insert_label(cur, (s3_key, label['Name'], label['Confidence'], boundingBox['Width'], boundingBox['Height'], boundingBox['Left'], boundingBox['Top'])) conn.commit() finally: cur.close() conn.close() # メインのLambdaハンドラ関数 def lambda_handler(event, context): s3_client = boto3.session.Session() s3_resource = s3_client.resource('s3') if event.get('httpMethod') == 'GET': return generate_presigned_url(s3_client, event, headers, context) if event.get('queryStringParameters') else get_labels_from_rds(headers, context) elif event.get('httpMethod') == 'POST': body = json.loads(event['body']) s3_key = body['imageS3Key'] response = detect_labels(s3_client, s3_resource, S3_BUCKET, s3_key) write_labels_to_rds(response, s3_key) return { 'statusCode': 200, 'headers': headers, 'body': json.dumps({ 'labels': [label['Name'] for label in response['Labels']], 'confidences': [label['Confidence'] for label in response['Labels']], 'boundingBoxes': [instance['BoundingBox'] for label in response['Labels'] for instance in label['Instances']] }) } else: return { 'statusCode': 400, 'headers': headers, 'body': json.dumps({'error': 'Invalid httpMethod'}) } # Amazon RDSからラベル情報を取得する関数 def get_labels_from_rds(headers, context): conn = get_db_connection() cur = get_db_cursor(conn) cur.execute("SELECT * FROM labels") rows = cur.fetchall() labels = [{'id': row[0], 'file_name': row[1], 'label': row[2], 'confidence': row[3], 'bounding_box_width': row[4], 'bounding_box_height': row[5], 'bounding_box_left': row[6], 'bounding_box_top': row[7]} for row in rows] try: cur.close() conn.close() finally: return { 'statusCode': 200, 'headers': headers, 'body': json.dumps({'labels': labels}), } # 署名付きURLを生成する関数 def generate_presigned_url(s3_client, event, headers, context): s3_client = boto3.client('s3') queryStringParameters = event['queryStringParameters'] filename = queryStringParameters['filename'] unique_key = filename presigned_url = s3_client.generate_presigned_url( 'put_object', Params={ 'Bucket': S3_BUCKET, 'Key': unique_key, 'ContentType': 'image/jpeg', }, ExpiresIn=3600 ) return { 'statusCode': 200, 'headers': headers, 'body': json.dumps({ 'presigned_url': presigned_url, 'imageS3Key': unique_key, }), }
「def lambda_handler(event, context):」がメインのハンドラ関数で条件に応じて他の関数に処理を振り分ける中核的存在です。
- HTTPメソッドがGETの場合
- URLにクエリパラメータが含まれている場合
- generate_presigned_url関数を呼ぶ
- URLにクエリパラメータが含まれていない場合
- get_labels_from_rds関数を呼ぶ
- URLにクエリパラメータが含まれている場合
- HTTPメソッドがPOSTの場合
- detect_labels関数を呼ぶ
- HTTPメソッドがGETでもPOSTでもない場合
- エラーメッセージを含むレスポンスを返す
また、環境変数を使用することで以下のような利点があります。
●設定の分離:
同じコードを異なる環境(開発、ステージング、本番など)で再利用することが容易になります。
●セキュリティ:
機密情報(APIキー、データベースのパスワードなど)を環境変数に保存すると、これらの情報がコードに直接書かれることを防ぐことができます。
●柔軟性とスケーラビリティ:
アプリケーションの設定を変更する必要がある場合、環境変数を更新するだけで済むため、新しいバージョンのコードをデプロイする必要がありません。
Lambdaの環境変数を設定する手順は以下です。
●Lambdaのコンソールから「設定」を選択
●画面左側メニューの「環境変数」を選択
●画面右側の「編集」を選択

これでLambda関数を使える、と思いたい所ですが、まだ必要な設定が残っています。
本アプリケーションのLambda関数では以下の4つのパッケージをインポートしています。
- os
- json
- boto3
- psycopg2
これらのパッケージの内でos、json、boto3はLambdaのランタイムに含まれているので直接インポートできますが、psycopg2は含まていないので、ユーザー側で準備する必要があります。
準備する手段としては主に以下の2通りです。
- Lambda関数コードと一緒にZIPファイルとしてアップロード
- Lambdaレイヤーの使用
本アプリケーションでは後者の「Lambdaレイヤーの使用」で準備します。
lambdaレイヤーを作成する前に、まずはpsycopg2に関して簡単に解説します。psycopg2とはPythonからPostgreSQLデータベースへのアクセスを可能にするライブラリです。psycopg2とpsycopg2-binaryという2種類の形式が存在しますが、psycopg2-binaryはpsycopg2ライブラリのスタンドアロンバージョンで特別なシステム依存関係が必要ないため、本アプリケーションではこちらを採用します。psycopg2の詳細は以下の公式ドキュメントをご覧ください。
それではLambdaレイヤーの作成に入ります。
Lambdaレイヤーとして作成するパッケージの実行環境は当然ではありますが、ローカル環境ではなくLambda実行環境です。従ってDockerを使用してLambda の実行環境を模倣するコンテナ内で依存関係をパッケージ化する方法でLambdaレイヤーを作成します。ホストOSがLinuxの場合は問題ありませんが、WindowsやMacOSの場合はDocker DesktopなどでDockerを使用できる環境を整えて下さい。Dockerを使用できる準備が整ったら以下のコマンドを順番に実行して下さい。以下の「echo "urllib3==1.26.6" >> requirements.txt」に関してですが、このコマンドはurllib3のバージョン2.0(2023年4月26日リリース)がOpenSSL 1.1.1より前のバージョンのサポートを停止したために含めています。
# ディレクトリ構造の作成 mkdir -p python/lib/python3.8/site-packages #依存関係の指定 echo "psycopg2-binary" > requirements.txt echo "urllib3==1.26.6" >> requirements.txt #Dockerを使用してAWSのLambda環境をシミュレートし、指定した依存関係をインストール docker run -v "$PWD":/var/task "public.ecr.aws/sam/build-python3.8" /bin/sh -c "pip install -r requirements.txt -t python/lib/python3.8/site-packages/; exit" #レイヤーの.zipファイルアーカイブの作成 zip -r mylambdalayer.zip python > /dev/null
これでmylambdalayerという名称で.zipファイルアーカイブ形式のLambdaレイヤーが作成されるので、アップロードしてLambda関数に追加するだけです。これの手順は本ブログの過去の記事に存在しますので以下をご覧ください。ただしランタイムはPython 3.8です。
以上でLambdaの設定は終了です。
4.6. Amazon API Gateway
4.6.1. Amazon API Gatewayとは
まず Amazon API Gatewayに関して簡単に解説します。
Amazon API GatewayはAWSが提供するフルマネージド型のAPI管理サービスです。
API Gatewayには以下のような特徴や利点があります。
■シームレスなスケーリング:
利用量に応じて自動的にスケーリング(拡張)します。
■フルマネージドサービス:
APIのデプロイ、管理、スケーリング、セキュリティなどの作業をAWSが行います。
■高度なセキュリティ:
認証と認可、APIキーの検証、オリジン間リソース共有(CORS)のポリシーの設定などでAPIに対する不正なアクセスを防ぎます。
■モニタリングとトラブルシューティング:
詳細なログと監視ツールを提供しており、APIのパフォーマンスをモニタリングします。
詳細は以下のAWSの公式ドキュメントをご覧下さい。
4.6.2. Amazon API Gatewayの設定
次に本アプリケーションに必要なAPI Gatewayの設定を具体的に解説します。
まずAWSマネジメントコンソールのホームからAPI Gatewayを選択します。
次に画面右上の「APIの作成」を選択して下さい。

次に画面中央のREST APIの「構築」を選択して下さい。

次に、各項目を以下のように設定して下さい。
●プロトコルの選択:REST
●新しいAPIの設定:新しいAPI
●名前と説明:適当な名前で大丈夫です。ただし、必ず入力する必要があります。
●エンドポイントタイプ:リージョン
●最後に「APIの作成」を選択して下さい。

次に、各項目を以下のように設定して下さい。
●画面左側のサイドメニュー:リソース
画面上部の「アクション」を選択して、表示されるメニューから「リソースの作成」を選択して下さい。画面右側に「新しい子リソース」というページが出現します。
●リソース名とリソースパス:適当な名前で大丈夫です。ただし、必ず入力する必要があります。
●「API Gateway CORSを有効にする」にチェックを入れて下さい。
●最後に「リソースの作成」を選択して下さい。これでリソースが作成されます。

次にリソースに必要なメソッドを追加します。
先ほど作成したリソースを選択してから「アクション」を選択すると表示されるメニューの中の「メソッドの作成」を選択して下さい。

メソッドを作成するプルダウンメニューが出現するので必要なメソッドを1つ選択してチェックマークを選択して下さい。

次に、各項目を以下のように設定して下さい。
●結合タイプ:Lambda関数
●Lambdaプロキシ統合の使用:チェックマーク
●Lambdaリージョン:Lambdaを配置したリージョンを選択
●Lambda関数:作成したLambda関数の名称
●デフォルトタイムアウトの使用:チェックマーク
●最後に「保存」を選択してから「OK」を選択して下さい。これでメソッドが作成されます。

これらの作業を必要なリソースとメソッドを作成するまで繰り返して下さい。
必要なリソースとメソッドを作成し終えたら「アクション」を選択して表示されるメニューから「APIのデプロイ」を選択して下さい。

次に、各項目を以下のように設定して下さい。
●デプロイされるステージ:新しいステージ
●ステージ名:適当な名前で大丈夫です。ただし、開発環境ならdev、本番環境ならprodなどと名前を付ければ分かりやすいです。
●最後に「デプロイ」を選択して下さい。
 以上でAPI Gatewayの設定は終了です。もしAPIに何らかの変更を加えた場合、必ずデプロイして下さい。そうしなければ加えた変更が反映されないので注意して下さい。
以上でAPI Gatewayの設定は終了です。もしAPIに何らかの変更を加えた場合、必ずデプロイして下さい。そうしなければ加えた変更が反映されないので注意して下さい。
5. フロントエンド側のセットアップ
5.1. フレームワーク
本アプリケーションはフロントエンドにVue.jsを使用していますが、もちろん他のフレームワーク(ReactやAngularなど)を使用しても問題なく開発できます。
5.2. 非同期処理の管理
本アプリケーションの処理フローは多数の非同期操作(API呼び出しやファイルアップロードなど)を含んでいます。これらの非同期操作を適切に管理するためには、Promiseやasync/awaitなどのJavaScriptの非同期処理の概念を適切に使用することが重要です。
6. 検証
それではいよいよ検証に入ります。本アプリケーションの処理フローは主に以下の3つに分けることができます。
❶Vue.jsで画像ファイルを選択することでAPI Gatewayを経由してLambdaに署名付きURLをリクエストする。Lambdaが署名付きURLを発行してAPI Gatewayを経由してVue.jsで署名付きURLを受け取る。
❷Vue.jsで署名付きURLを使用して画像をS3にアップロードと同時にAPI Gatewayを経由してLambdaにRekognitionで検出されたラベルと各ラベルに対する信頼度とバウンディングボックスの情報を取得してRDSに書き込むことをリクエストする。LambdaがRekognitionを使用して画像から検出されたラベルと各ラベルに対する信頼度とバウンディングボックスの情報を取得してからpsycopg2を使用してAmazon RDSに接続して画像から検出されたラベルと各ラベルに対する信頼度とバウンディングボックスの情報を書き込んだ後Amazon RDSとの接続を解除する。API Gatewayを経由してLambdaからRekognitionとAmazon RDSでの作業が終了した報告をVue.js受け取る。
❸Vue.jsでAPI Gatewayを経由してLambdaにAmazon RDSに存在するデータベースのテーブルの情報を取得することリクエストする。Lambdaがpsycopg2を使用してAmazon RDSに接続してデータベースに存在するテーブルの情報を取得する。API Gatewayを経由してLambdaからデータベースのテーブルの情報をVue.jsで受け取る。
❶~❸を検証するために以下のような簡単なUIをVue.jsで作成しました。
●「Select an image」で画像ファイルを選択します。
●「UPLOAD」ボタンで画像ファイルをS3にアップロードします。
●「DATABASE」ボタンでデータベースのテーブルの情報を画面に表示します。

検証用の画像は以下のような画像を用意しました。左上に猫、右上に犬、左下に亀、右下に鳥が位置する画像です。

まず処理フロー❶を検証します。画像ファイルを選択して署名付きURLを受け取れるでしょうか。
 無事受け取れたようです。
無事受け取れたようです。
次に処理フロー❷を検証します。画像ファイルをS3にアップロードして無事作業完了の報告を受け取れるでしょうか。
 無事受け取れたようです。
無事受け取れたようです。
最後に処理フロー❸を検証します。Rekognitionから検出したラベルと信頼度と境界ボックスの情報を記録したデータベースに存在するテーブルの情報を表示できるでしょうか。
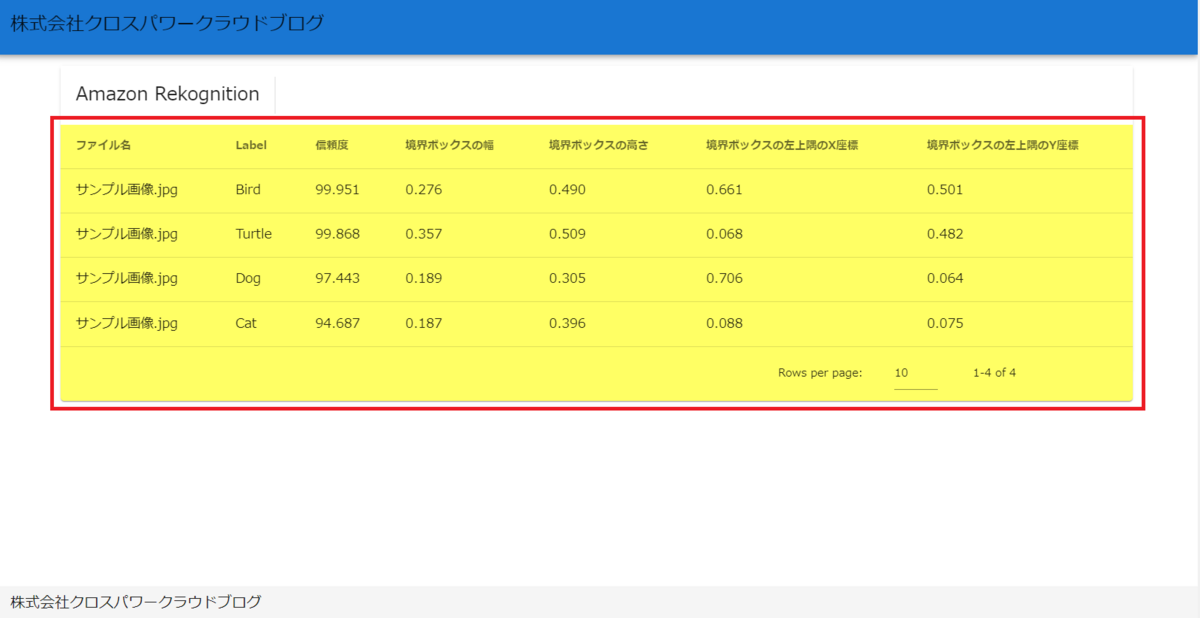 無事表示できたようです。
無事表示できたようです。
Rekognitionで検出できる各項目に関して簡単に解説します。
●ラベル:
Rekognitionが画像やビデオから識別できるオブジェクト、シーン、アクティビティなどの種類を指します。画面にBird(鳥)、Turtle(亀)、Dog(犬)、Cat(猫)と表示されているので正しく検出できています。
●信頼度:
Rekognitionがラベルを画像に割り当てる自信度を表しています。スコアが高いほど、ラベルが正確に画像を表している可能性が高いです。画面に表示されている信頼度は全て90%以上なので非常に自信を持ってラベルを検出したことが分かります。
●境界ボックスの幅と高さ:
境界ボックス(画像内の特定のオブジェクトや人物を囲む四角形の領域)の幅と高さは、それぞれその四角形の横幅と縦の大きさを指します。境界ボックスの幅と高さは、画像全体のサイズに対する相対的な値(最小値が0で最大値は1)で表されます。
●境界ボックスの左上隅のX座標とY座標:
境界ボックスの座標は左上の点の座標を指し示します。画像の左上が原点(0,0)となり、画像の横幅(X軸)と縦幅(Y軸)に対して、それぞれ0から1までの相対的な値が割り当てられます。原点から右に行くとX軸の値が増え、下に行くとY軸の値が増えます。
7. おわりに
AWSは複数のサービスを組み合わせて「まさに求めているシステム」を構築することができるので非常に便利だと感じました。他のAWSサービスも組み合わせれば更に自由度の高いシステムを構築できそうです。