










こんにちは。katoです。
今回はAmazon Rekognitionを利用して、画像の解析や統計情報の取得を行っていきたいと思います。
概要
今回構築していく画像解析のシステムは下図の様になります。

S3のバケットに画像が配置されると、それがトリガーとなってRekognitionによるラベル判定が行われます。 ラベルの情報はDynamoDBに格納され、Lambdaを経由してAmazon ElasticSearchに連携されます。
手順
それでは、さっそく設定を行っていきたいと思います。
今回はRekognitionが利用可能なバージニア北部(us-east-1)で構築を行っていきます。
S3バケットの作成
画像を保存するバケットを作成します。 特に設定は必要ありませんが、Rekognitionが利用できるリージョンに作成するようにしてください。
DynamoDBテーブルの作成
次に、ラベルデータを保存するDynamoDBのテーブルを作成します。
今回は、プライマリーキーを「image(文字列)」、ソートキーを「label(文字列)」としてテーブルを作成します。 同時に大量のデータを解析するような場合などには、キーを「ID(文字列)」などにし、ランダム文字列等で一意なデータとして登録することをお勧めいたします。
テーブルを作成したら、ストリームを有効化します。 今回のシステムでは、Kibanaへの反映を(ほぼ)リアルタイムで行いたいのでDyanmoDBストリームを利用します。 ストリームの管理から新旧イメージを選択しストリームを有効化します。

Lambda関数の作成(ラベル判定用)
DynamoDBの設定までできたら、画像を判定するためのLambda関数を作成します。
「一から作成」を選択し、Python 2.7で関数を作成します。
ロールは、S3、Rekognition、DynamoDBへの権限を付与したものを選択します。
関数を作成したら、インラインにて下記コードに編集します。
import json import urllib import boto3 print('Loading function') s3 = boto3.client('s3') rekognition = boto3.client('rekognition') dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('dynamodb-table-name') def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key'].encode('utf8')) detect = rekognition.detect_labels( Image={ 'S3Object': { 'Bucket': bucket, 'Name': key } } ) labels = detect['Labels'] for num in range(len(labels)): label_name = labels[num]['Name'] label_confidence = int(labels[num]['Confidence']) if label_confidence >= 70: table.put_item( Item={ 'image': key, 'label': label_name, 'confidence': label_confidence, } ) else: pass
上記の関数が行っているのは下記の操作になります。
①トリガーから画像の名前とバケット名を取得 ②画像の名前とバケット名をRekognitionに渡してラベル判定 ③判定結果をDynamoDBに格納
ちなみに、今回はラベルの判定で信頼性が70%以下のものは対象外としています。
Lambda関数の編集が完了したら、トリガーとなるS3の設定を行います。
「トリガーの追加」からS3を選択します。

S3を選択すると、トリガーの設定が表示されるので、下記の様に設定しトリガーを追加します。
バケット名: 画像の保存バケット イベントタイプ: オブジェクトの作成(すべて) トリガーの有効化: オン

ここまでの設定で、「画像のアップロードを検知 → ラベル判定 → DynamoDBへの登録」までの仕組みが出来上がります。
Amazon ElasticSearchの構築
ラベルの統計情報を可視化するためにAmazon ElasticSearchを利用します。
ドメインの作成は通常通り行うのみですが、配置ネットワークにのみ注意して下さい。 このあとに作成するLambda関数からアクセスできるようネットワークの設定を行ってください。 パブリックアクセスの場合は、特に設定の必要はありませんが、VPCに配置する場合はLambda関数からドメインが見えるように設定する必要があります。
Lambda関数の作成(ElasticSearch連携用)
ElasticSearchのドメインの作成が完了したら、DynamoDBからElasticSearchに連携するためのLambda関数を作成します。
zipアップロードでの関数作成となりますが、zipアップロードの方法は下記ブログを参考にしてください。
利用するモジュールは同じなので、ここでは省略させていただきます。
DynamoDB to Amazon Elastic Search
コードのみ少し異なりますので、以下のコードに書き換えてください。
#!/usr/bin/python import requests import json from aws_requests_auth.aws_auth import AWSRequestsAuth import random import string import datetime from urlparse import parse_qs print('Loading function') def lambda_handler(event, context): auth = AWSRequestsAuth( aws_access_key='xxxxxxxxxxxxxxxxxxxx', aws_secret_access_key='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx', aws_host='elastic-search-endpoint', aws_region='us-east-1', aws_service='es' ) for record in event['Records']: dynamodb = record['dynamodb'] if "NewImage" in dynamodb.keys(): strlabel = (json.dumps(record['dynamodb']['NewImage']['label']['S'])) strconfidence = str((json.dumps(record['dynamodb']['NewImage']['confidence']['N']))) strimage = str((json.dumps(record['dynamodb']['NewImage']['image']['S']))) label = strlabel.replace("\"", "") confidence = strconfidence.replace("\"", "") image = strimage.replace("\"", "") now = datetime.datetime.now().strftime("%Y-%m-%dT%H:%M:%S%z") n = 5 random_str = ''.join([random.choice(string.ascii_letters + string.digits) for i in range(n)]) url = ("https://elastic-search-endpoint/index/number/"+random_str) res = requests.post(url, data=json.dumps({"@timestamp": now, "label": label, "confidence": int(confidence), "image": image}), auth=auth)
コードのzipアップロード後にDynamoDBストリームをトリガーとして追加すれば設定は完了です。 トリガーの追加方法は上記のブログに記載してありますので、そちらを参照して下さい。
動作確認
正常に動作している場合には、S3にオブジェクトをアップロードすることで、DynamoDBとElasticSearchにデータが登録されるはずです。
今回は、画像ファイルを50枚ほど同時にS3にアップロードしてみます。
アップロード後にDynamoDBを確認してみると。。。

ちゃんと登録できております。
ElasticSearchの方は。。。

インデックスが登録されております。
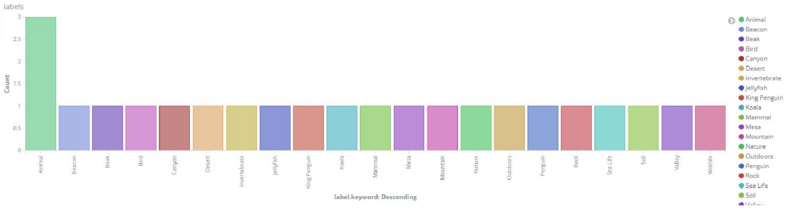
最後に、Kibanaで可視化してみます。

上記は単純にラベルキーワードでカウントを取っているだけですが、ラベルごとのカウント数や全体の割合などをわかりやすく可視化することが出来ました。
おまけ
ElasticSearchでラベルの統計を取得できたので、この情報をWEBページに反映させる例をご紹介いたします。 今回はラベルの統計から人気のコンテンツを判定し、WEBページに表示するという簡単なものを作成します。 概要は省略致しますので、スクリプトおよびphpコードを参考程度にご覧ください。
スクリプト
#!/usr/bin/python import json from elasticsearch import Elasticsearch es = Elasticsearch("https://elastic-search-endpoint") aggs = {"count": {"terms": {"field": "label.keyword","order": {"_count": "desc"},"size": 5}, "aggs": {"max_add": {"sum": {"field": "length"}}}}} res = es.search(index="labels", body={"query": {"match_all": {}}, "aggs": aggs}) top_labels = res['aggregations']['count']['buckets'] images = [] for num in range(len(top_labels)): res = es.search(index="labels", body={"query": {"match": {"label":top_labels[num]['key']}}}) for num2 in range(len(res['hits']['hits'])): image = res['hits']['hits'][num2]['_source']['image'] images.append(image) sort_images = {} for num3 in sorted(set(images), key=images.index): sort_images.update({num3:images.count(num3)}) print max(sort_images.items(), key=lambda x:x[1])[0]
上記スクリプトはラベルのカウント数TOP5を取得し、最もマッチするイメージを決定しています。
PHP
<?php $out = shell_exec('./script.py'); require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\S3\Exception\S3Exception; $bucket = 'bucket-name'; $keyname = trim($out); $s3 = S3Client::factory(); try { $result = $s3->getObject(array( 'Bucket' => $bucket, 'Key' => $keyname )); header("Content-Type: {$result['ContentType']}"); echo $result['Body']; } catch (S3Exception $e) { echo $e->getMessage() . "\n"; } ?>
上記PHPはスクリプトの結果をもとに、AWS SDK for PHPを利用してS3からイメージを表示させています。
動作確認
まずは以下のようなデータの際に表示される画像を確認してみます。
WEBページにアクセスしてみると以下の様なペンギンの画像が表示されました。

次にいくつか画像を追加し、以下の様なラベルの統計となった場合に表示される画像を確認してみます。

WEBページに再度アクセスしてみると。。。

画像が変わりました。 ラベルの統計情報がしっかりとWEBページに反映されております。
上記の方法を応用すれば、画像の投稿サイトなどにおいて、人気コンテンツや流行のコンテンツを判定し、サイトのトップに表示させたりするような仕組みが可能となります。
まとめ
今回はRekognitionを利用した、画像データの統計システムを構築してみました。
おまけとしてご紹介したような用途以外にも、ラベルをキーワードとした画像の検索システムなど、様々な用途に応用ができるのではと感じました。
Rekognitionは東京リージョンではまだ利用できませんが、便利なサービスとなっているのでご興味のある方は一度お試しになってみてはいかがでしょうか。
