










はじめまして、新入社員の小川です。
最近、iPhone の写真が膨大になってきました。
写真をバックアップする際、フォルダ整理が面倒だと感じませんか?
今回は、そんな悩みを解決するために、
Amazon Rekognition を使用してフォルダ整理を行いたい思います。
大まかな流れ
0.Rekognition 概要
1.S3 バケットを作成
2.IAM ロールの作成
3.Lambda を作成
4.実行
0.Rekognition 概要
Amazon Rekognition は、高精度の画像・動画分析サービスです。
今回は、Amazon Rekognition を使用して、
画像内にある物体を検出し、ラベルを出力します。
例えば、下記の画像に対して、ラベルの検出を行います。

すると、以下のような出力結果となります。

今回は、この「検出されたラベル」をフォルダ名にして、
写真を整理してみたいと思います。
1.S3 バケットを作成
以下の2つのバケットを作成します。
・画像をアップロードする、専用バケット(rekognition-target-bucket)
・画像をフォルダ整理後、保存するバケット(rekognition-output-bucket)
※2つのバケットを同一にすると、Lambda を呼び出す際に
アップロード / 保存を何度も繰り返す可能性があります。
回避するために、3.3 トリガーの設定 にて追加設定を行う必要があります。
1-1. S3 を開く
「バケットを作成」をクリックします。
1-2. バケット名を入力
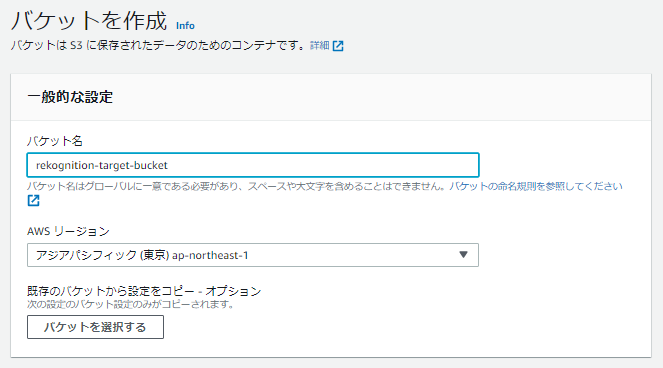
それ以外の項目はデフォルトで進めます。
1-3. バケットを作成
「バケットを作成」ボタンをクリックします。
S3 バケットが作成されました。

2.IAM ロールの作成
後で作成するLambda のアクセス許可を行うために、事前に作成しておきます。
2-1. ポリシーを作成
「ポリシーを作成」ボタンをクリックします。

2-2. JSON の記述
ポリシーの作成画面に移動します。
「JSON」を選択します。

以下の権限を付与します。
・2つのバケットに対して、GetObject / PutObject の許可
・Rekognition のフルアクセス
以下のJSON を記述します。
※ s3: GetObject のリソースには、アップロード用のバケットを、
s3: PutObject のリソースには、保存用のバケットを指定してください。
"Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::rekognition-target-bucket/*" }, { "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": "arn:aws:s3:::rekognition-output-bucket/*" }, { "Effect": "Allow", "Action": [ "rekognition:*" ], "Resource": "*" } ] }
記述が終わったら、「次のステップ:タグ」ボタンをクリックします。
2-3. タグを追加
今回は追加せずに進みます。
「次のステップ:確認」ボタンをクリックします。

2-4. ポリシーの確認
ポリシー名を入力します。
「ポリシーの作成」ボタンをクリックします。

IAM ポリシーが作成されました。

2-5. IAM ロールの作成
「ロールを作成」ボタンをクリックします。
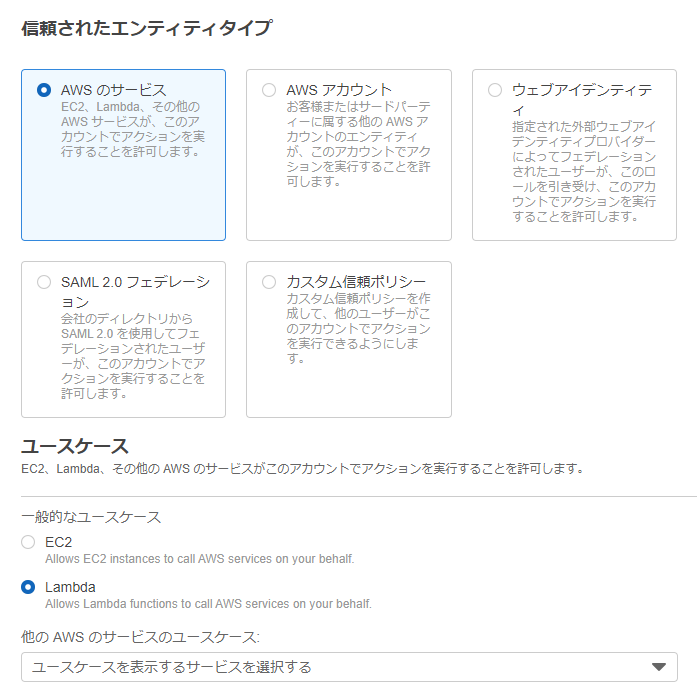
エンティティタイプは、「AWS のサービス」を選択します。
ユースケースに「Lambda」を選択して、「次へ」をクリックします。
2-6. 許可を追加
先ほど作成したポリシーを選択して、「次へ」をクリックします。
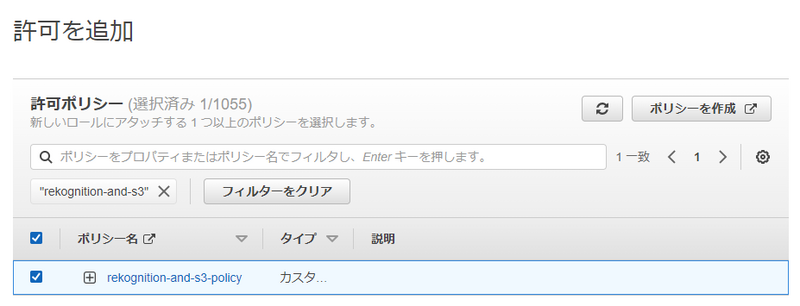
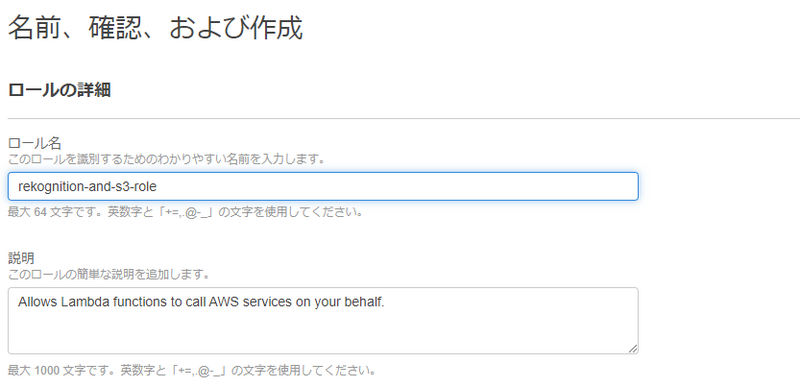
2-7. ロール名を入力
ロール名を入力して、「ロールを作成」ボタンをクリックします。
3.Lambda を作成
「関数の作成」ボタンをクリックします。

3-1. 関数の作成
関数名、ランタイム(今回はPython 3.9 を選択)を入力します。

「デフォルトの実行ロールの変更」をクリックします。
実行ロールの選択を行います。
実行ロールは「既存のロールを使用する」を選択し、先ほど作成したロールを選択します。

画面下部の「関数の作成」ボタンをクリックします。
関数が作成されました。

3-2. Lambda コーディング
Lambda 関数に、以下のコーディングを行います。
output_bucket の値は、先ほど作成した、保存用のバケット名に変更してください。
import boto3 import urllib.parse def lambda_handler(event, context): # バケット名と画像ファイル名の取得 trigger_bucket = event['Records'][0]['s3']['bucket']['name'] output_bucket = "rekognition-output-bucket1" photo = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') photo_name = photo.split("/")[-1] # ラベルの受け取り client = boto3.client('rekognition') response = client.detect_labels(Image={'S3Object':{'Bucket':trigger_bucket,'Name':photo}}, MaxLabels=1) label = response['Labels'][0]['Name'] # フォルダ移動 client = boto3.resource('s3') client.Bucket(trigger_bucket).download_file(photo, "/tmp/{}".format(photo_name)) client.Bucket(output_bucket).upload_file("/tmp/{}".format(photo_name), "{0}/{1}".format(label, photo_name)) return True
最後に、「Deploy」ボタンをクリックします。
コーディングが完了しました。

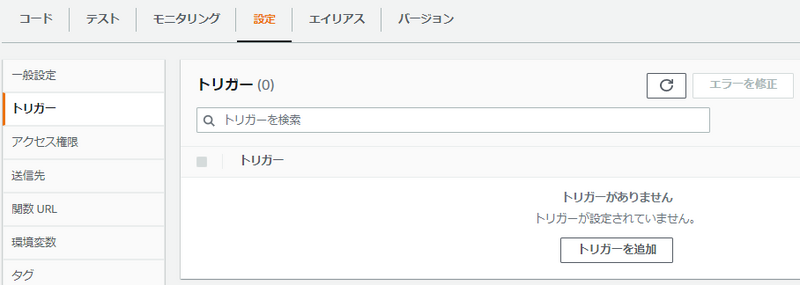
3-3.トリガーの指定
「設定」タブに移動し、「トリガー」を選択します。
「トリガーを追加」ボタンをクリックします。
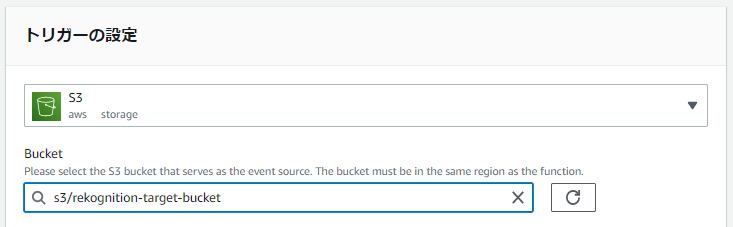
トリガーにS3 を選択します。
「Bucket」欄に、アップロード用のS3 バケットを選択します。
※ アップロード用のバケットと、保存用のバケットを同一にする場合、
「Prefix - オプション」に、以下のようにフォルダ名を記述します。

これで、images フォルダにアップロードされたファイルのみ、
Lambda のトリガーを設定できます。
実行の際には、images フォルダを作成し、アップロードを行ってください。
4.実行
以上で、フォルダ整理を行う機能は完成しました。
実際にアップロードしてみましょう。
アップロード用のバケットに、写真をアップロードします。
「アップロード」ボタンをクリックします。
ファイルを選択し、「アップロード」ボタンをクリックします。
※ 今回は、iPhone から転送した写真を使用しました。

保存用のバケットを確認すると...
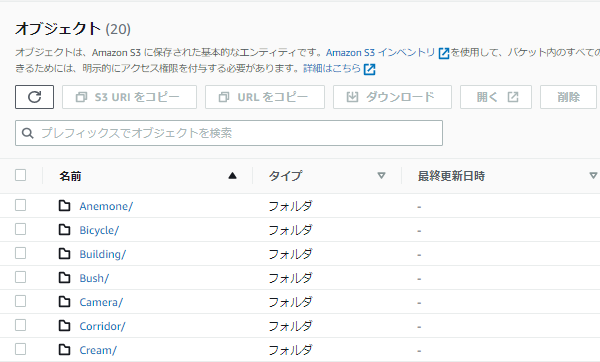
無事、Amazon Rekognition で取得したラベルが、
フォルダ名となってバケットに保存されました!
補足
Amazon Rekognition は、JPEG とPNG のみ対応しております。
今回、iPhone から転送した写真を使用しました。
そのため、拡張子がHEIC の写真などは、Lambda 内でエラーが発生しました。
エラー内容は、CloudWatch のログイベントに記録されています。

適宜、拡張子の変換を行った後に再度、実行してみてください。
参考:「よくある質問 - Amazon Rekognition」
おわりに
今回は Amazon Rekognition を使用して、写真のフォルダ整理を行ってみました。
iPhone の写真が増えてきたなと感じた方など、
気になる方は是非、作成してみてください。
