










こんにちは
今回の記事はQuickSightでデータソースとして利用できるRedshiftやAthenaを利用したテーマとなります。
前回は、Quicksightの導入から公開までをテーマとしているので、そちらもぜひご覧ください。
Redshift
データを取り込むためにRedshiftのクラスターを起動してサンプルのデータを投入します。
Redshiftの準備では以下の入門ガイドがおすすめです。
この入門ガイドに従ってクラスターを起動すると、複数テーブルをもったデータベースができあがります。
データもそれなりの量がとりこめるのでこの後紹介するQuickSightでの視覚化もやりごたえ?があります。
クラスターを起動できたらQuickSightの出番になります。
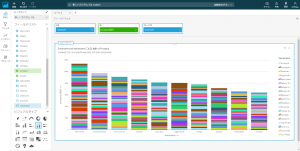
Redshiftをデータソースとすると以下のようにテーブル単位でデータセットを作成することができます。

ここまでくればあとは項目レベルの話になるのでcsvファイルと同じように視覚化できます。

複数のテーブルについて分析をかけたい場合はどのようにすればよいのでしょうか。
その方法としてQuickSightはテーブルの選択以外に、SQLによるデータセットの作成を提供しています。

複数テーブルを結合したデータセットを利用してもQuickSightでの視覚化の使い勝手は変わりません。
Athena
Redshiftと同様にデータソースとなるAthenaを作成しましょう。
AthenaはS3に配置されたファイルをクエリすることができるサービスなので、まずはS3にcsvファイルを配置します。
今回利用するデータはe-Statで公開されている国勢調査のcsv※ファイルを用います。
※出典:政府統計の総合窓口(e-Stat)(https://www.e-stat.go.jp/)
S3に配置したcsvファイルはこのようにAthenaのテーブルとしてデータを取り込むことができます。

データがクエリできることを確認します。
これでデータソースの準備が完了しました。

データセットの作成方法はRedshiftと同様にテーブルの選択か、SQLを使用するかを選べます。
今回は単体のcsvファイルで完結しているデータなのでテーブルとして取り込みます。

※Athenaをデータソースとして利用する場合、Athenaとの接続だけでなくS3との接続も許可しておく必要があります。

取り込んだ後は同じように視覚化できます。

おわりに
今回は実際に利用されそうなRedshiftやAthenaとの接続をメインに取り上げました。
これらのデータソースとの接続自体は簡単に行うことができて、そのあとのQuickSight上での視覚化や分析に集中できることがお分かりいただけたかと思います。
自分で試しているときも、データソースとの接続よりもRedshiftのサンプルデータの把握や視覚化に時間を割いていました。
興味が出た方は実際に動かしてみてはいかがでしょうか。


