










こんにちは。utsugiです。今回は、オンプレミスのOracleのデータを、Data Pumpを利用してRDS for Oracleに移行する方法について考えていきたいと思います。
Oracle自体のユーティリティとして馴染み深く、データ移行と聞いた際に真っ先に思い浮かぶ方もいらっしゃるのではないでしょうか。オンプレミス環境とは少し勝手が違いますが、ツールの優秀さは変わりません。
目次
∗ Data Pumpについて ∗ OracleからRDSへのData Pumpを利用したデータ移行の流れ ∗ Data Pumpを利用した移行のメリット ∗∗ オンプレミス環境の設定を変更する必要がない ∗∗ オンプレミス環境と直接繋ぐ必要がない ∗∗ 移行ツールのトラブルシューティングがしやすい ∗∗ 移行に柔軟性がある ∗ Data Pumpを利用した移行のデメリット ∗∗ ダウンタイムが長くなる ∗∗ RDSの容量が一時的に多く必要になる ∗ まとめ
Data Pumpについて
既にご存知の方も多いでしょうが、Data PumpはOracle純正のエクスポート(expdp)/インポート(impdp)ユーティリティです。Data Pumpが出てくるまでもオリジナルのエクスポート(exp)/インポート(imp)ユーティリティは提供されていましたが、Data Pumpは、高パフォーマンス、取捨選択の柔軟性等が強調されています。
【Data Pumpの特徴】 ・基本的(※)にデータベースサーバ上にダンプファイルが存在している必要がある ・移行元/先のオンプレミス/クラウド環境の組み合わせに制限はない ・異種間のデータベースの移行に対応していない ・対象データの一括移行に対応している ・更新差分のレプリケーションには対応していない ・定義情報の移行に対応している ※ネットワーク・モードを利用すれば、ダンプファイルは不要になります。
Data Pumpは更新差分のレプリケーションには対応していないため、基本的に、データ更新を停止してエクスポート/インポートを行う必要があります。
FLASHBACK_TIMEというオプションを利用すれば、指定した時点での一貫性のあるダンプファイルを作成することはできますが、結局、その指定時点以降の差分はインポート後に吸収する必要があります。
このように、どうしてもダウンタイムは長くなってしまいますが、移行対象の取捨選択や、定義の移行等も行うことができます。
OracleからRDSへのData Pumpを利用したデータ移行の流れ
それでは、おおよその流れについて記載します。オブジェクト定義等も移行する場合でも、データのみを移行する場合でも、流れとしては同様です。
図: Data Pumpを利用してデータを移行する
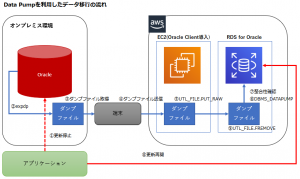
①更新停止 Data Pumpはレプリケーション機能を持っていないため、データ移行中にデータ変更が発生しないよう、移行作業開始前に更新を停止します。
②expdp expdpを利用して、移行元のOracleからデータをエクスポートし、ダンプファイルを作成します。データのみの場合は、CONTENT=DATA_ONLYを指定します。
③ダンプファイル取得
④ダンプファイル送信 ②で作成したダンプファイルを、中継用の端末を経由してEC2に持っていきます。なお、今回は中継用の端末を用意していますが、ネットワーク的にも直接繋ぐことができれば、この端末を用意する必要はありません。 また、Tsunami UDP Protocolを利用することで、転送速度の向上を期待することもできます。
⑤UTL_FILE.PUT_RAW Oracle ClientがインストールされたEC2上から、UTL_FILE.PUT_RAWを利用して、④で送信されたダンプファイルを、さらにRDSに送信します。実際には、スクリプトを利用しての送信となります。 スクリプトのサンプルについてはStrategies for Migrating Oracle Databases to AWSのTransferring Files to an Amazon RDS Instanceセクションに記載されていますが、下記のスクリプトの、3行目~6行目を環境に応じて変更します。
use DBI; my $RDS_PORT=4080; my $RDS_HOST="myrdshost.xxx.us-east-1-devo.rds-dev.amazonaws.com"; my $RDS_LOGIN="orauser/orapwd"; my $RDS_SID="myoradb"; my $dirname = "DATA_PUMP_DIR"; my $fname = $ARGV[0]; my $data = "dummy"; my $chunk = 8192; my $sql_open = "BEGIN perl_global.fh := utl_file.fopen(:dirname,:fname,'wb',:chunk);END;"; my $sql_write = "BEGIN utl_file.put_raw(perl_global.fh,:data,true); END;"; my $sql_close = "BEGIN utl_file.fclose(perl_global.fh); END;"; my $sql_global = "create or replace package perl_global as fh utl_file.file_type; end;"; my $conn = DBI->connect('dbi:Oracle:host='.$RDS_HOST.';sid='.$RDS_SID.';port='.$RDS_PORT, $RDS_LOGIN, '') || die ( $DBI::errstr . "\n") ; my $updated=$conn->do($sql_global); my $stmt = $conn->prepare($sql_open); $stmt->bind_param_inout(":dirname", \$dirname, 12); $stmt->bind_param_inout(":fname", \$fname, 12); $stmt->bind_param_inout(":chunk", \$chunk, 4); $stmt->execute() || die($DBI::errstr . "\n"); open(INF,$fname) || die "\nCan't open $fname for reading: $!\n"; binmode(INF); $stmt = $conn->prepare($sql_write); my %attrib = ('ora_type','24'); my $val=1; while ($val >0) { $val = read(INF, $data, $chunk); $stmt->bind_param(":data", $data, \%attrib); $stmt->execute() || die ($DBI::errstr . "\n"); }; die "Problem copying: $!\n" if $!; close INF || die "Can't close $fname: $!\n"; $stmt = $conn->prepare($sql_close); $stmt->execute() || die ($DBI::errstr . "\n");
上記のようなスクリプトを作成後、スクリプトを実行することで、ファイルを送信できます。
perl <スクリプト名> <ダンプファイル名>
⑥DBMS_DATAPUMP あとは、EC2を経由してRDSに送信されたダンプファイルを実際にインポートするだけです。 こちらも、サンプルについてはStrategies for Migrating Oracle Databases to AWSのTransferring Files to an Amazon RDS Instanceセクションに記載されています。 DBMS_DATAPUMP等を参照しながら、インポート要件にあったスクリプトに修正します。
⑦整合性確認 インポートが正常に終了した時点で、対象のデータは移行元と移行先で同期がとれた状態になりますが、欠落等が発生していないか、データの整合性を確認します。
⑧更新再開 データの整合性まで確認出来たら、アプリケーションの更新先を移行先に変更します。
⑨UTL_FILE.FREMOVE 最後に、今回利用したダンプファイルは不要になったため、容量の節約のためにも、ダンプファイルを削除します。
EXEC UTL_FILE.FREMOVE('DATA_PUMP_DIR', '<ダンプファイル名>');
Data Pumpを利用した移行のメリット
オンプレミス環境の設定を変更する必要がない
基本的に、ツールを使用するためだけに、移行元の運用に大きく影響するような特別な設定変更を行う必要がありません。既に移行元でツールを利用した実績もあるのではないでしょうか。 現行システムの動作に対する影響を最小限にしたいと考えた際、これは大きなメリットになるものと思われます。
オンプレミス環境と直接繋ぐ必要がない
移行方法にもよりますが、基本的に、オンプレミス環境のOracleとクラウド環境のRDSを直接繋ぐ必要はありません。一度、データをファイルとして抜き出せさえすれば、RDSに対するデータ投入方法は比較的自由であるためです。 セキュリティ要件的に、オンプレミス環境とクラウド環境を直接繋ぐことが難しい場合、これは大きなメリットになるものと思われます。
移行ツールのトラブルシューティングがしやすい
Data Pumpと言えば、Oracle管理者にとっては非常に馴染み深いツールです。そのため、ツール自体の仕様に精通している方も多く、また、インターネット上にもナレッジが多く存在しています。 したがって、Data Pump自体で問題が発生した場合でも、対処法が比較的容易に見つかりやすいという利点があります。
移行に柔軟性がある
Oracle純正ツールであり、テーブル名・スキーマ・表領域等の変更をしたり、特定のオブジェクトを除外したり極めて自由度が高いです。 そのまま移行するのであれば、そういったカスタマイズを用いることはないかもしれませんが、移行を機にした構造の変更等にも比較的容易に対応することができます。
Data Pumpを利用した移行のデメリット
ダウンタイムが長くなる
基本的に、完全に移行元と移行先のデータを同期させる場合(通常の移行ケース)、移行開始から移行終了までの間、システムは利用できない状態になります。 また、ダウンタイムは移行データ量に比例して長くなるため、最小限のダウンタイムを求める移行には向きません。
RDSの容量が一時的に多く必要になる
基本的に、Data Pumpに利用するダンプファイルは、インポート対象のOracleが稼働するサーバに存在する必要があります。つまり、今回のデータ移行で言うと、RDS上に配置する必要が出てきます。 後で削除すれば最終的な容量はデータサイズの分だけで問題ありませんが、単純計算で、一時的にインポートするデータの約2倍のディスク領域を要するということになります。
まとめ
今回は、少し例を挙げつつData Pumpでのデータ移行について見てきました。 やや工程が多くなり、ダウンタイムも比較的長めになってしまいますが、慣れ親しんだツールを利用した柔軟な移行を考えた場合、有力候補と言えるのではないでしょうか。

