










みなさん、こんにちは、こんばんは。 いよいよS3 Selectが一般公開されました。 S3に置いたファイルへSQLを投げ、データを抽出できるサービスです。 当記事ではどんなSQLが投げられるのか検証してみましたので、その結果をお伝えしたいと思います。
Pythonでのプログラム実装部分は別の記事に記載してありますので、そちらをご参照ください。
検証用にデータを用意します。 ちょっと見にくいので、説明を進めながら、見返してもらえればと思います。
s3select.json
{ "_id": "5ad023505514e15120684996", "age": 34, "eyeColor": "green", "name": { "first": "Dalton", "last": "Alvarado" }, "tags": [ "laboris", "pariatur", "sunt", "exercitation", "esse" ], "friends": [ { "id": 0, "name": "Kristen Jenkins" }, { "id": 1, "name": "Burch Daugherty" }, { "id": 2, "name": "Wynn Brown" } ], "favoriteFruit": "banana" } { "_id": "5ad02350becf165e64c27ad9", "age": 23, "eyeColor": "blue", "name": { "first": "Martha", "last": "Graham" }, "tags": [ "ad", "aliqua", "enim", "eu", "ipsum" ], "friends": [ { "id": 0, "name": "Adams Mccullough" }, { "id": 1, "name": "Minerva Kent" }, { "id": 2, "name": "Bishop Bradley" } ], "favoriteFruit": "banana" } { "_id": "5ad023507622d8404af14399", "age": 34, "eyeColor": "green", "name": { "first": "Juliette", "last": "Holmes" }, "tags": [ "sunt", "anim", "nisi", "est", "ipsum" ], "friends": [ { "id": 0, "name": "Massey Nash" }, { "id": 1, "name": "Skinner Blanchard" }, { "id": 2, "name": "Barber Dalton" } ], "favoriteFruit": "strawberry" } { "_id": "5ad02350c8fff17c3fb1dcb9", "age": 22, "eyeColor": "brown", "name": { "first": "Patrice", "last": "Doyle" }, "tags": [ "esse", "ex", "magna", "minim", "velit" ], "friends": [ { "id": 0, "name": "Bush Santiago" }, { "id": 1, "name": "Jasmine Howe" }, { "id": 2, "name": "Rebecca Sellers" } ], "favoriteFruit": "apple" } { "_id": "5ad02350259ad16576bf2335", "age": 38, "eyeColor": "brown", "name": { "first": "Bolton", "last": "Clark" }, "tags": [ "elit", "ad", "nulla", "commodo", "laboris" ], "friends": [ { "id": 0, "name": "Deidre Hayes" }, { "id": 1, "name": "James Casey" }, { "id": 2, "name": "Duran Spencer" } ], "favoriteFruit": "strawberry" } { "_id": "5ad02350f126c16eb7e76a48", "age": 28, "eyeColor": "green", "name": { "first": "Guadalupe", "last": "Young" }, "tags": [ "et", "duis", "enim", "aliqua", "aute" ], "friends": [ { "id": 0, "name": "Owen Ford" }, { "id": 1, "name": "Carrillo Harrison" }, { "id": 2, "name": "Tricia Castillo" } ], "favoriteFruit": "strawberry" } { "_id": "5ad023500cf7eeb255c32926", "age": 30, "eyeColor": "green", "name": { "first": "Anthony", "last": "Brooks" }, "tags": [ "aliquip", "minim", "fugiat", "ut", "cupidatat" ], "friends": [ { "id": 0, "name": "Flores Mcpherson" }, { "id": 1, "name": "Kimberley England" }, { "id": 2, "name": "Selma Padilla" } ], "favoriteFruit": "strawberry" }
まずは普通のSQLです。こちらは問題なく通りますね。
select * from s3object s
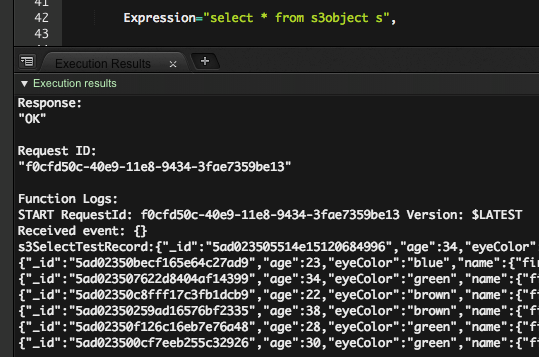
続いてwhere句を付けてみます
select * from s3object s where s.eyeColor = 'green'
こちらも問題なく実行できました。きちんと絞り込めています。
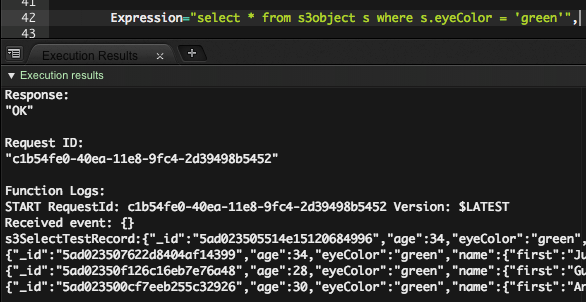
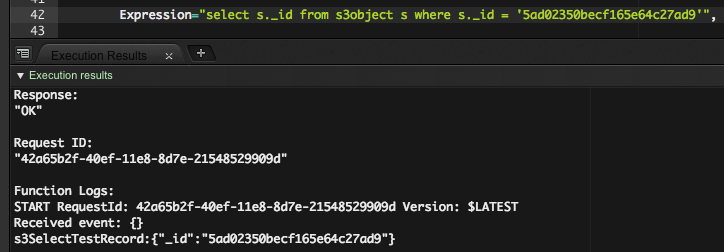
記号から始まる列を指定してみます。
select s._id from s3object s where s._id = '5ad02350becf165e64c27ad9'
問題なく実行できました。
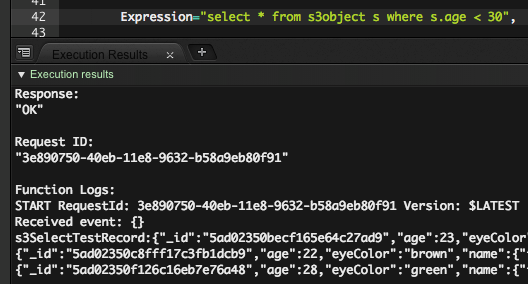
where句に数字を入れてみます
select * from s3object s where s.age < 30
問題ありませんね。
order by句を入れてみます。
select * from s3object s order by s.age
エラーになってしまいました。並び替えはできないようです。
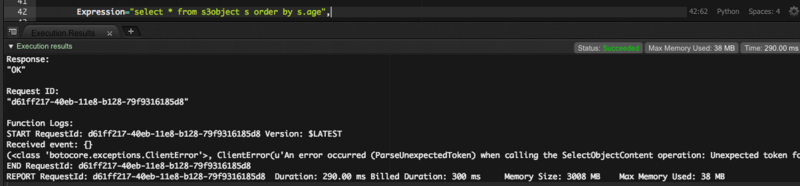
エラー内容:
(
気を取り直してここからが本番です。配列を検索してみましょう。
select * from s3object s where 'elit' in s.tags
配列の検索は普通にできました。in句の左右が逆なのが気持ち悪いですが、これはこれで理にかなっているので良しです。

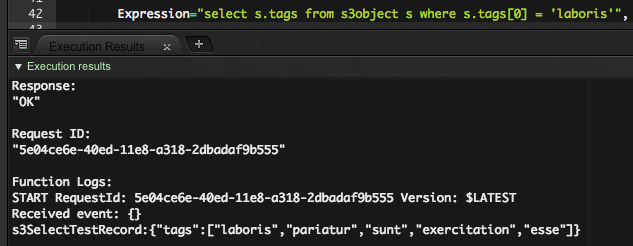
配列の要素を指定して検索してみましょう。
select s.tags from s3object s where s.tags[0] = 'laboris'
配列の要素での検索も普通にできました。
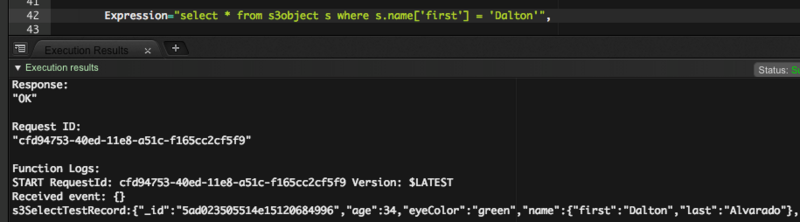
ネストした構造体で検索してみましょう。
select * from s3object s where s.name['first'] = 'Dalton'
え!本当にできちゃうの!!!SQLとしては不気味ですが、普通にできました。
ここまでできちゃうと逆に気になるのがパフォーマンスです。
色々できる分、遅いんじゃないかと思い検証してみました。
{id:0, val:"0", name:"name0", age:0} {id:1, val:"1", name:"name1", age:1} {id:2, val:"2", name:"name2", age:2} ...
0から10,000,000まで連番で作った577M、1000万件のJSONファイルです。
この中からvalが1のデータと9,999,999のデータを抜き出します。
select * from s3object s where s.val in ('1', '9999999')
7秒で結果が返ってきました。
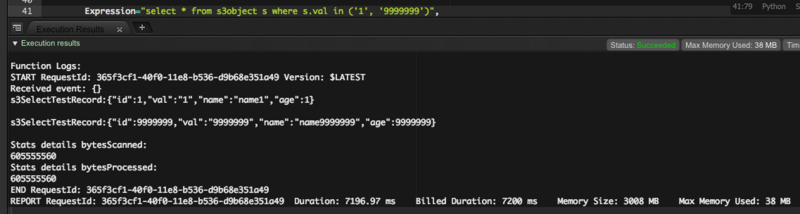
インデックスなんて機能は無いのでフルスキャンしてあり、ファイルサイズ分だけスキャンしたようです。 でも1000万件を7秒でスキャンするのは驚異的速度です。 RDBでは数十分から数時間は音信不通になるレベルなので、いかに凄いかが分かると思います。 みなさんも是非使ってみてください。
